



Purpose
A Support Vector Machine is a prevalent and widely used machine learning model. It helps perform linear and non-linear classification, regression, and outlier detection. SVMs are particularly well suited for classification of complex but small or medium-sized datasets (thousands).
Key sentences
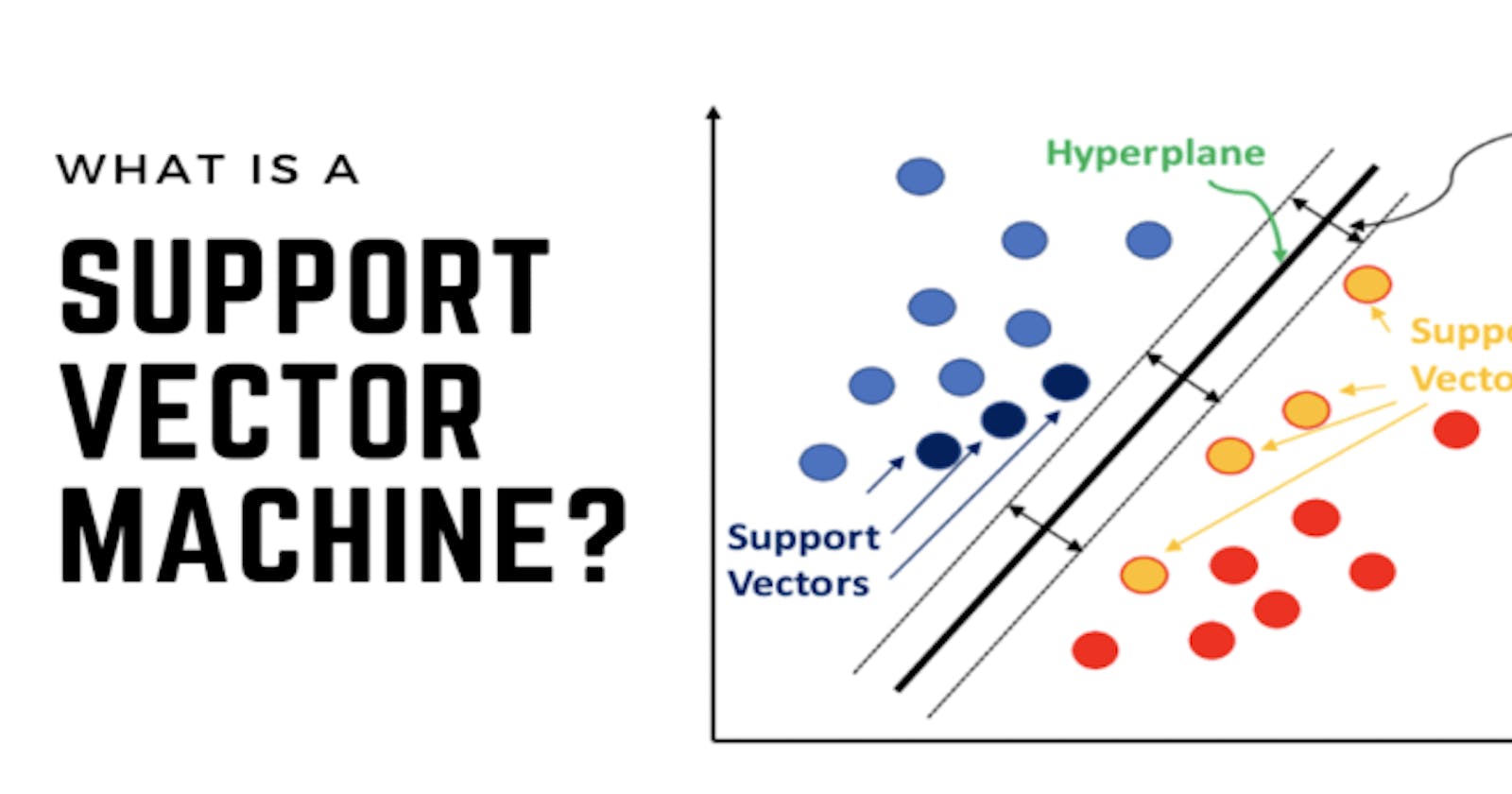
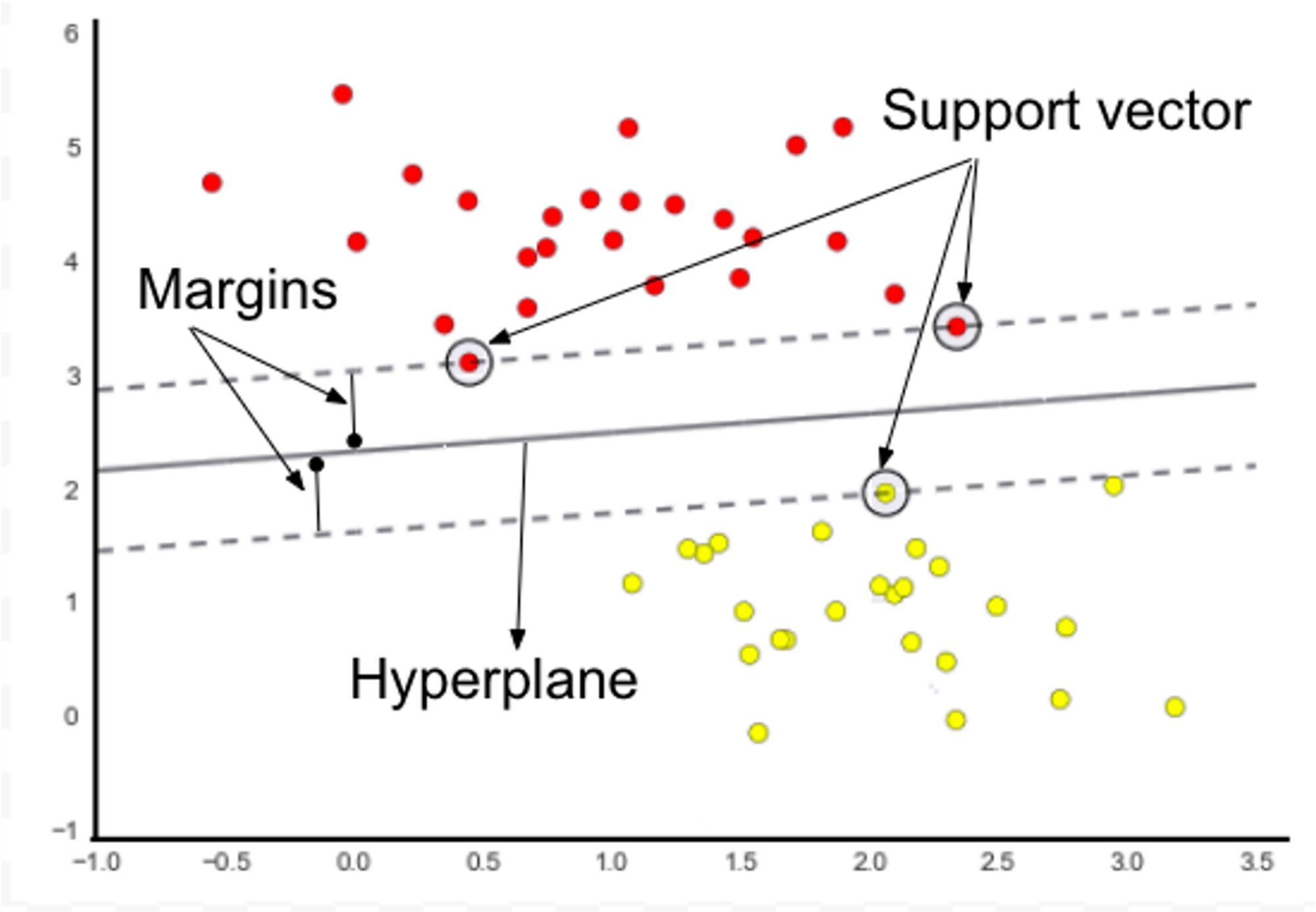
You can think of an SVM classifier as fitting the widest possible street between the classes. This is called large margin classification.
Adding more training instances "off the street" will not affect the decision boundary at all. It is fully determined by the instances located on the edge of the street. these instances are called support vectors.
A support vector is any instance located on the street, including its border. Any instance that is not a support vector has no influence and won't affect the decision boundary, computing the predictions only involves the support vectors, not the whole training set.
If your model is overfitting, you can try regularizing it by reducing C.
Unlike Logistic Regression classifiers, SVM classifiers do no output probabilities for each class.
Adding polynomial features is simple to implement and can work great with all sorts of machine learning algorithms (not just SVMs), but at a low polynomial degree it cannot deal with very complex datasets, and with a high polynomial degree it creates a huge amount of features, making the model too slow. Fortunately, you can apply a technique called kernel trick to make it possible to get the same result as if you added many polynomial features, even with very high degree polynomials, without actually having to add them.=
SVM Regression tries to fit as many instances as possible on the street while limiting margin violation (instances off the street)
For large-scale nonlinear problems, you may want to consider using neural networks instead of SVMs.
An SVM classifier can output the distance between the instance and the decision boundary, and you can use this as a confidence score.
If you set probability=True when creating an SVM in Scikit-Learn, then after training it will calibrate the probabilities using Logistic Regression on the SVM's scores. This will add the predict_proba() and predict_log_proba() methods to the SVM.
Key takeaways
Linear and Non-Linear SVM classification
SVMs are sensitive to feature scales. It's recommended to scale the features (i.e using scikit StandardScaler) to get better decision boundaries.
We could find a way to impose having all the instances off the street, but this will likely cause the model to become sensitive to outliers and difficult to generalize. This is usually called hard margin classification.
It's preferable to use a flexible model and opt for a soft margin classification. Ending up finding a good balance between keeping the street as large as possible and limiting the margin violation (instances in the middle of the street).
The margin violation can be controlled with the C hyperparameter, the smaller the value the larger the street.
LinearSVC is slow against large datasets. One can use SGDClassifier that applies stochastic gradient descent. it doesn't converge as fast as LinearSVC, but it can be useful to handle huge datasets that do not fit in memory or to handle online classification tasks.
Sometimes, some classes aren't linearly separable. One approach to handling non-linear datasets is to add more features, such as polynomial features. This can be achieved with a Pipeline containing a PolynomialFeatures transformer and followed by a StandardScaler and a LinearSVC.
Nonlinear datasets can be approached with different techniques (polynomial, similarity features (GRBF), ..). The main challenge is to find the right technique for balancing dataset size and computation cost. The kernel trick is usually the recommended approach to look for and is supported in Scikit-Learn"SVC" classifier class. As there are many different kinds of kernels, you should always try the linear kernel first, especially if the training set is very large or if it has plenty of features.